Hardware Abstractions
the CIMFlow ISA implements a three-level hardware abstraction hierarchy complemented by a flexible instruction set design.
Each abstraction level interfaces with the corresponding stages in the compilation and simulation infrastructure, providing architectural specifications that guide both compilation optimization and simulation execution.
Chip Level
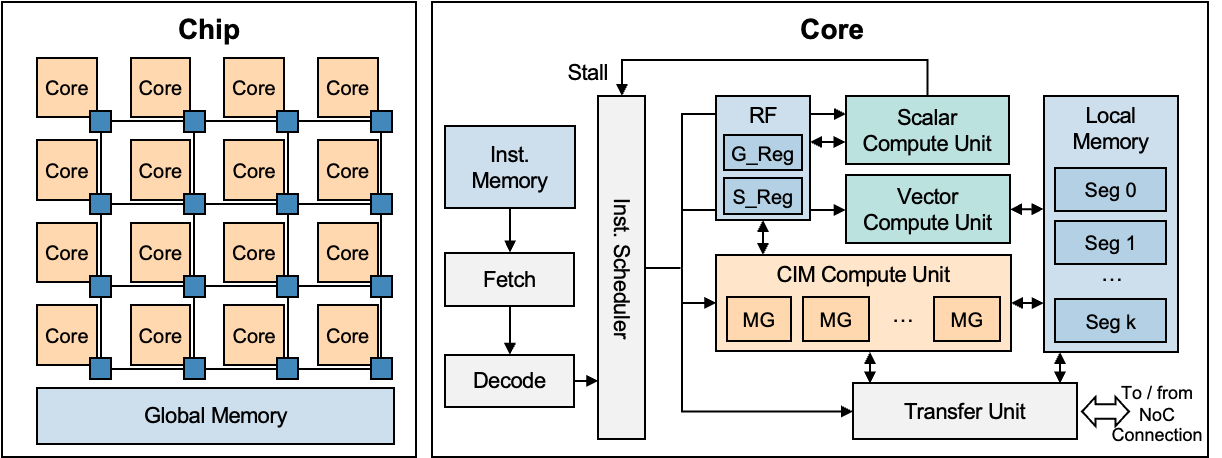
The architecture consists of multiple cores interconnected through a Network-on-Chip (NoC) structure, facilitating synchronous inter-core communication and global memory access.
This organization enables scalable workload distribution and flexible inter-core pipelining, with each core functioning as a basic unit of program execution with its own instruction control flow.
- Scale: Total number of cores
C = P * Q(by default,PandQare equal). - Communication: Performs point-to-point synchronous communication between cores, meaning no other operations can be executed simultaneously during the communication process.
- Bandwidth: On-chip communication bandwidth is denoted as
B.
Core Level
The core-level abstraction defines the organization of hardware resources, encompassing instruction memory, various compute units, register files (RFs), and local memory.
To facilitate efficient memory management and architectural extensibility, CIMFlow implements a unified address space across both global and local memories.
In addition, the local memory is divided into segments to efficiently handle the input and output of DNN layers.
The register file consists of general-purpose registers (G_Reg) for instruction-level access and special-purpose registers (S_Reg) for operation-specific functions.
Unit Level
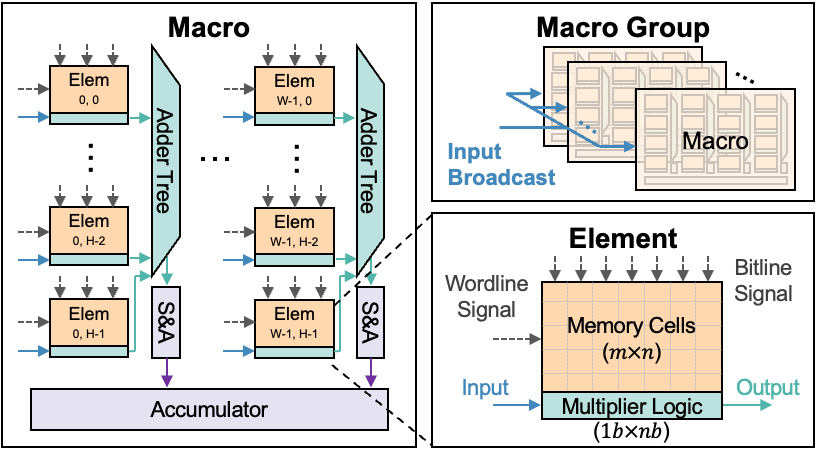
At unit level, the CIM compute unit incorporates multiple macro groups (MGs) that support weight duplication and flexible spatial mapping strategies.
Within each MG, weights are typically organized along the output channel, enabling efficient input data broadcast across macros for parallel in-memory MVM operations.
The vector compute unit handles auxiliary DNN operations such as activation, pooling, and quantization.
The scalar compute unit executes control flow operations through scalar arithmetic computations.
CIM Compute Unit
- Composed of
TMacro Groups. Within each Macro Group,KMacros store distinct filter weight information while sharing the same input. - A weight replication strategy is adopted across different Macro Groups to enable the parallel processing of inputs (data parallelism).
Vector Compute Unit
- Executes operations such as quantization, activation, accumulation, and residual calculation.
Scalar Compute Unit
- Performs address calculation and participates in control logic decisions, including instruction stalling and branching.